
5 Awkward Questions for the Production-End of the DevOps Pipeline
DevOps isn’t just about development, the creation of new code and capabilities, there’s also the need to release to the production environment in a way that’s both swift and “safe” – protecting business operations in line with the organization’s appetite for risk.
Much has been said and written about the left-to-right DevOps pipeline, most of it about the starting left-hand side where the developer and version control system trigger a continuous integration process to create a new test environment. But wait, what about the “production side”?
This awkward, right-hand end of the pipeline (the shaded-red area in the diagram below) is often skirted around or skimmed over when good practices are shared in blogs or at events.
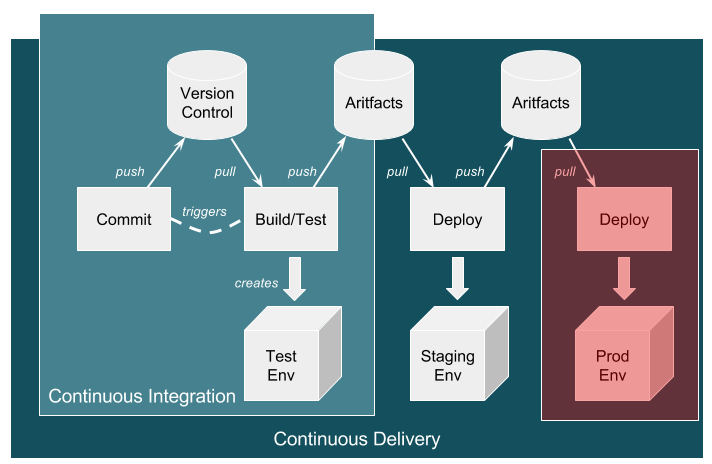
Source: https://ukcloud.pro
However, at some point, anyone “doing” DevOps will have to address the following five, potentially awkward, questions:
- How are changes applied to production?
- What about the production data?
- Is production really updated continuously and many times a day?
- Are new production environments created with every release?
- How do we roll back production changes?
In this blog, I’d like to tackle each of these in turn.
1. How Are Changes Applied to Production?
The continuous integration/continuous delivery (CI/CD) movement is all about smaller and less risky releases to production, and there is a myriad of ways of achieving it. But, this is different to how it was done pre-CI/CD.
Pre-DevOps, changes were often deployed in one of two extreme ways. First, you make a little tweak to a running system under change management. Or, second, you make a big bang implementation to production that requires a reboot. And prayers. Lots of prayers.

The DevOps way to change production uses a CI/CD pipeline as a mechanism to test and release software through environments using consistent mechanisms so there’s less stress and more success. But the key part of this is the size of the change. It’s somewhere in the middle between the non-DevOps “tweak” and “bang.”
DevOps doesn’t release tweaks into production, because these tweaks are historically applied without proper testing and inconsistent deployment techniques; and deploying a tweak into production is often different to doing it in test and staging, usually because test and staging are nothing like production.
DevOps also doesn’t release big bangs into production because they are notoriously hard to back out, and the failure of the release has what’s known as a large blast radius.
The DevOps “Goldilocks release process” gets it just right by deploying releases that range (yes, there’s a range here, there’s not one outfit for all occasions) from small artifacts such as Java Archive Files (JARs) up to whole environments…but there’s another important difference…
DevOps also provides for mechanisms to introduce releases with easy testing for failure and easy back out, called blue-green deployments.
When you add up the Goldilocks release unit with the new release process, the DevOps release to production is very different from non-DevOps scenarios.
2. What About the Production Data?
There are three important facts here. Number one, if you’re not careful when you release to production, then you could delete your production database. Number two, test data is different to production data. Number three, if you release production database updates at the same time as the code, it causes back out/rollback issues.
- There have been repeated production outages caused by companies erroneously deleting their own production database. How is this even possible? Easy – when you’re using a DevOps pipeline, sometimes humans forget to set unique environment variables such as which databases are test versus staging versus production. Sounds incredible, but it happens. So, when the scripts get twisted, that deployment to staging manages to drop to production instead, because it has the wrong database name.
- Test data is different to production, so problems might not manifest themselves until running in production. In this cloud era, getting copies (snapshots) of production databases is a doddle, so this issue should be eliminated.
- Mixing code rollouts with database updates sounds logical but makes the deployment artifact too near to big bang, so doing tick-tock releases of “add new database column” first, then a separate release for “add new code to use new database column” second is a common release pattern.
3. Is Production Really Updated Continuously and Many Times a Day?
It depends on your release bundle. If the releases are limited to small artifact changes that are easily rolled back, then ”yes.” If changes are bundled, and towards the big bang end of the spectrum, then it’s more likely the answer to this is “no.”
For example, if you have a release that updates the color of your website banner, then that’s fine because it’s easy to test and roll back. If you have a release that changes the instance type of your web servers in AWS, that’s also fine because it’s easy to test and roll back.
Another aspect of DevOps continuous delivery is that it’s about having the capability to push to production every time, not that you always choose to use it.
You could choose to not push releases during business hours and in effect changes will queue up – but they will still be individual changes! You must resist the temptation to bundle them up into one package and apply them in a different manner to which they’ve been released and tested in other environments.
4. Are New Production Environments Created with Every Release?
In the cloud, with infrastructure as code and high levels of automation and capabilities, this is absolutely possible. But not everyone is so sophisticated so there isn’t one easy answer to this. Instead it’s more of a spectrum of possibilities from which you need to pick what’s best for you. Here’s some examples to choose from:
- We build a brand-new production environment side-by-side with current production and enable database synchronization. Then we use DNS or load balancing to switch-over environments using blue/green roll out.
- We use automation tools to apply change sets to production application and infrastructure components. We limit changes to make rollback simple and predictable.
- Our change set for production is small in this release – so No. We just update – or our change set is huge for this upgrade – so Yes, we create a new environment and do a cutover.
5. How Do We Roll Back Production Changes?
To start, make sure you deploy small-scale changes that are easily backed out. Rollback is completely determined by the size and complexity of the artifact, and the rollout process. No matter what the dynamics, the goal is to make rollout and rollback as simple, predictable, and stress-free as possible.
Different methods sometimes have to be used because of the type of change:
- Is it a minor, non-disruptive change to an application configuration?
- Is it a major addition of new functionality?
- Is it a new infrastructure component?
- Can we deploy using feature toggles?
There are rollout strategies such as blue-green deployment to leverage:
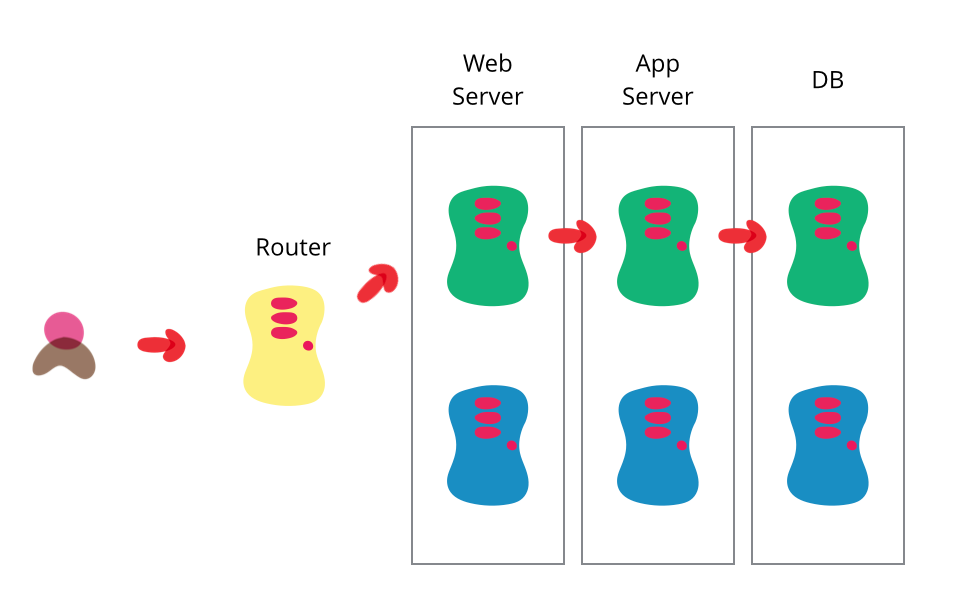
Source: Martin Fowler, Blue-Green Deployment
In blue-green deployments, a new production environment is deployed beside the existing, live production environment. Live data is synchronized and a cut-over is done at the network level such as changing which load balancer a website points to. In this case, to roll back, all you do is switch back to the “old” production environment. The risk is then limited to the stale data generated between the cut-over and rollback times.
So that’s my five awkward questions. Which do you have better answers for? And what other awkward questions need answering? Please let me know in the comments.






